cs231N lecture10 recurrent neural network
RNN
$ 每一步都使用相同的f函数和参数集。 $
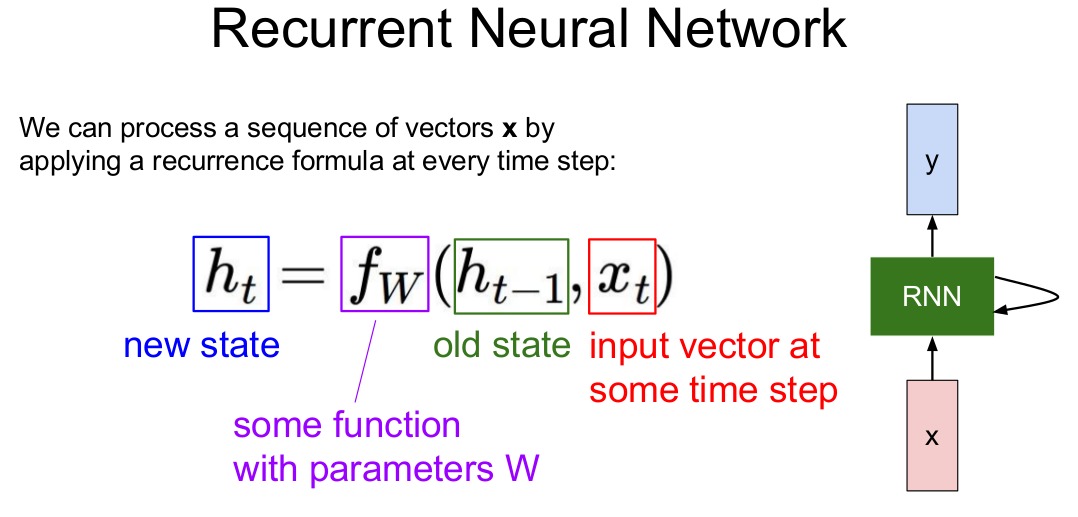


$ 图片解释:第t层 hidden layer -> h_t, 第t层 input layer -> x_t $
$W_{hh} 和 W_{xh} 第一维长度不一定相同,第二维长度相同。$
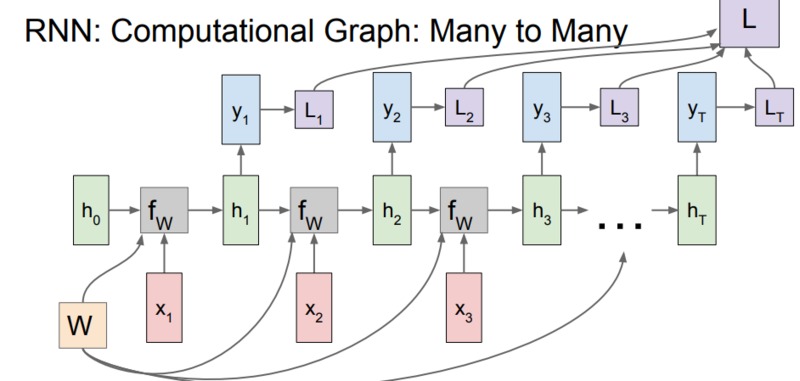
$图片解释: loss 的计算: 计算每个层的loss,最后都相加起来成为最终的loss。$
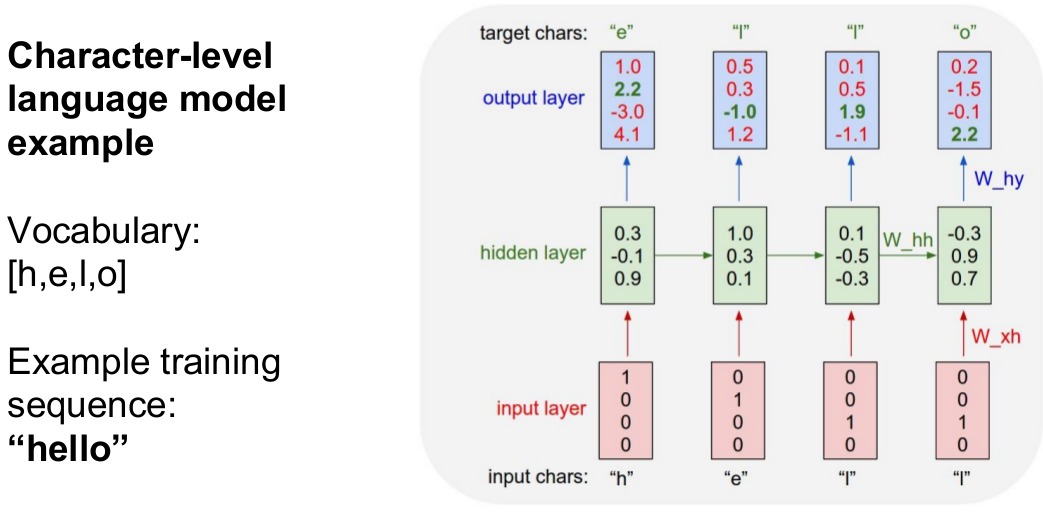
min-char-rnn
$ 如果直接是全局在计算的话,会发现显存或内存不够,而且会计算的十分的久,因为训练集是十$ $分巨大的。那么有什么办法呢?truncated,也就是分块计算,因为我们的sequence输入是有个$ $时间顺序的,假设我们设置一个chunk是100,那么我们跑了100个字母,后计算这100个的bac $ $kpropagation,然后再跑100,现在有了200了,但是我们计算的是后100的backpropagation$ $,如此反复。这便是seq_length的含义。$


$ 代码解释: 给RNN输入巨量的文本,然后让其建模并根据一个序列中的前一个字母,给出下一$ $个字母的概率分布。$
"""
Minimal character-level Vanilla RNN model. Written by Andrej Karpathy (@karpathy)
BSD License
"""
import numpy as np
import jieba
# data I/O
data = open('/home/multiangle/download/280.txt', 'rb').read() # should be simple plain text file
data = data.decode('gbk')
data = list(jieba.cut(data,cut_all=False))
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
print ('data has %d characters, %d unique.' % (data_size, vocab_size))
char_to_ix = { ch:i for i,ch in enumerate(chars) }
ix_to_char = { i:ch for i,ch in enumerate(chars) }
# hyperparameters
hidden_size = 200 # size of hidden layer of neurons
seq_length = 25 # number of steps to unroll the RNN for
learning_rate = 1e-1
# model parameters
Wxh = np.random.randn(hidden_size, vocab_size)*0.01 # input to hidden
Whh = np.random.randn(hidden_size, hidden_size)*0.01 # hidden to hidden
Why = np.random.randn(vocab_size, hidden_size)*0.01 # hidden to output
bh = np.zeros((hidden_size, 1)) # hidden bias
by = np.zeros((vocab_size, 1)) # output bias
def lossFun(inputs, targets, hprev):
"""
inputs,targets are both list of integers.
hprev is Hx1 array of initial hidden state
returns the loss, gradients on model parameters, and last hidden state
"""
xs, hs, ys, ps = {}, {}, {}, {}
hs[-1] = np.copy(hprev) # hprev 中间层的值, 存作-1,为第一个做准备
loss = 0
# forward pass
for t in range(len(inputs)):
xs[t] = np.zeros((vocab_size,1)) # encode in 1-of-k representation
xs[t][inputs[t]] = 1 # x[t] 是一个第t个输入单词的向量
# 双曲正切, 激活函数, 作用跟sigmoid类似
# h(t) = tanh(Wxh*X + Whh*h(t-1) + bh) 生成新的中间层
hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t-1]) + bh) # hidden state tanh
# y(t) = Why*h(t) + by
ys[t] = np.dot(Why, hs[t]) + by # unnormalized log probabilities for next chars
# softmax regularization
# p(t) = softmax(y(t))
ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t])) # probabilities for next chars, 对输出作softmax
# loss += -log(value) 预期输出是1,因此这里的value值就是此次的代价函数,使用 -log(*) 使得离正确输出越远,代价函数就越高
loss += -np.log(ps[t][targets[t],0]) # softmax (cross-entropy loss) 代价函数是交叉熵
# 将输入循环一遍以后,得到各个时间段的h, y 和 p
# 得到此时累积的loss, 准备进行更新矩阵
# backward pass: compute gradients going backwards
dWxh, dWhh, dWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why) # 各矩阵的参数进行
dbh, dby = np.zeros_like(bh), np.zeros_like(by)
dhnext = np.zeros_like(hs[0]) # 下一个时间段的潜在层,初始化为零向量
for t in reversed(range(len(inputs))): # 把时间作为维度,则梯度的计算应该沿着时间回溯
dy = np.copy(ps[t]) # 设dy为实际输出,而期望输出(单位向量)为y, 代价函数为交叉熵函数
dy[targets[t]] -= 1 # backprop into y. see http://cs231n.github.io/neural-networks-case-study/#grad if confused here
dWhy += np.dot(dy, hs[t].T) # dy * h(t).T h层值越大的项,如果错误,则惩罚越严重。反之,奖励越多(这边似乎没有考虑softmax的求导?), y = Why * hs[t] + by
dby += dy # 这个没什么可说的,与dWhy一样,只不过h项=1, 所以直接等于dy
dh = np.dot(Why.T, dy) + dhnext # backprop into h y_t = Why*H_t + b_y H_t = tanh(Whh*H_(t-1) + bh + Whx*X_t), 第一阶段求导
# f(z) = tanh(z), f(z)' = 1 − (f(z))^2
dhraw = (1 - hs[t] * hs[t]) * dh # backprop through tanh nonlinearity 第二阶段求导,注意tanh的求导, hs[t] = Whh*H_(t-1) + bh + Whx*X_t
dbh += dhraw # dbh表示传递 到h层的误差
dWxh += np.dot(dhraw, xs[t].T) # 对Wxh的修正,同Why
dWhh += np.dot(dhraw, hs[t-1].T) # 对Whh的修正
dhnext = np.dot(Whh.T, dhraw) # h层的误差通过Whh不停地累积
# dh表示d_ht,H_t = tanh(Whh*H_(t-1) + bh + Whx*X_t),y对于H_(t-1)的倒数为np.dot(Whh.T, dhraw)
for dparam in [dWxh, dWhh, dWhy, dbh, dby]:
np.clip(dparam, -5, 5, out=dparam) # clip to mitigate exploding gradients
return loss, dWxh, dWhh, dWhy, dbh, dby, hs[len(inputs)-1]
#基于之前的文本,生成新的文本
def sample(h, seed_ix, n):
"""
sample a sequence of integers from the model
h is memory state, seed_ix is seed letter for first time step
"""
x = np.zeros((vocab_size, 1))
x[seed_ix] = 1
ixes = []
for t in range(n):
h = np.tanh(np.dot(Wxh, x) + np.dot(Whh, h) + bh) # 更新中间层
y = np.dot(Why, h) + by # 得到输出
p = np.exp(y) / np.sum(np.exp(y)) # softmax
ix = np.random.choice(range(vocab_size), p=p.ravel()) # 根据softmax得到的结果,按概率产生下一个字符
x = np.zeros((vocab_size, 1)) # 产生下一轮的输入
x[ix] = 1
ixes.append(ix)
return ixes
n, p = 0, 0
mWxh, mWhh, mWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why)
mbh, mby = np.zeros_like(bh), np.zeros_like(by) # memory variables for Adagrad
smooth_loss = -np.log(1.0/vocab_size)*seq_length # loss at iteration 0
while True:
# prepare inputs (we're sweeping from left to right in steps seq_length long)
if p+seq_length+1 >= len(data) or n == 0: # 如果 n=0 或者 p过大
hprev = np.zeros((hidden_size,1)) # reset RNN memory 中间层内容初始化,零初始化
p = 0 # go from start of data # p 重置
inputs = [char_to_ix[ch] for ch in data[p:p+seq_length]] # 一批输入seq_length个字符
targets = [char_to_ix[ch] for ch in data[p+1:p+seq_length+1]] # targets是对应的inputs的期望输出。
# sample from the model now and then
if n % 100 == 0: # 每循环100词, sample一次,显示结果
sample_ix = sample(hprev, inputs[0], 200)
txt = ''.join(ix_to_char[ix] for ix in sample_ix)
print ('----\n %s \n----' % (txt, ))
# forward seq_length characters through the net and fetch gradient
# hprev 有一个缺点:状态向量来自于前一个数据块
loss, dWxh, dWhh, dWhy, dbh, dby, hprev = lossFun(inputs, targets, hprev)
smooth_loss = smooth_loss * 0.999 + loss * 0.001 # 将原有的Loss与新loss结合起来
if n % 100 == 0: print ('iter %d, loss: %f' % (n, smooth_loss)) # print progress
# perform parameter update with Adagrad
for param, dparam, mem in zip([Wxh, Whh, Why, bh, by],
[dWxh, dWhh, dWhy, dbh, dby],
[mWxh, mWhh, mWhy, mbh, mby]):
mem += dparam * dparam # 梯度的累加
param += -learning_rate * dparam / np.sqrt(mem + 1e-8) # adagrad update 随着迭代次数增加,参数的变更量会越来越小
p += seq_length # move data pointer
n += 1 # iteration counter, 循环次数
CNN+RNN
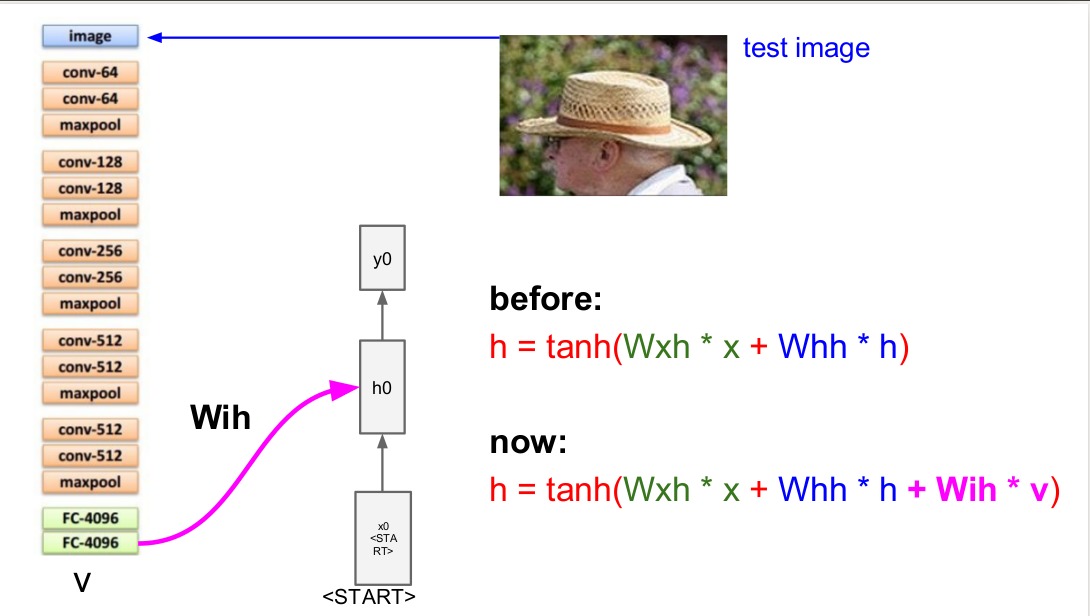
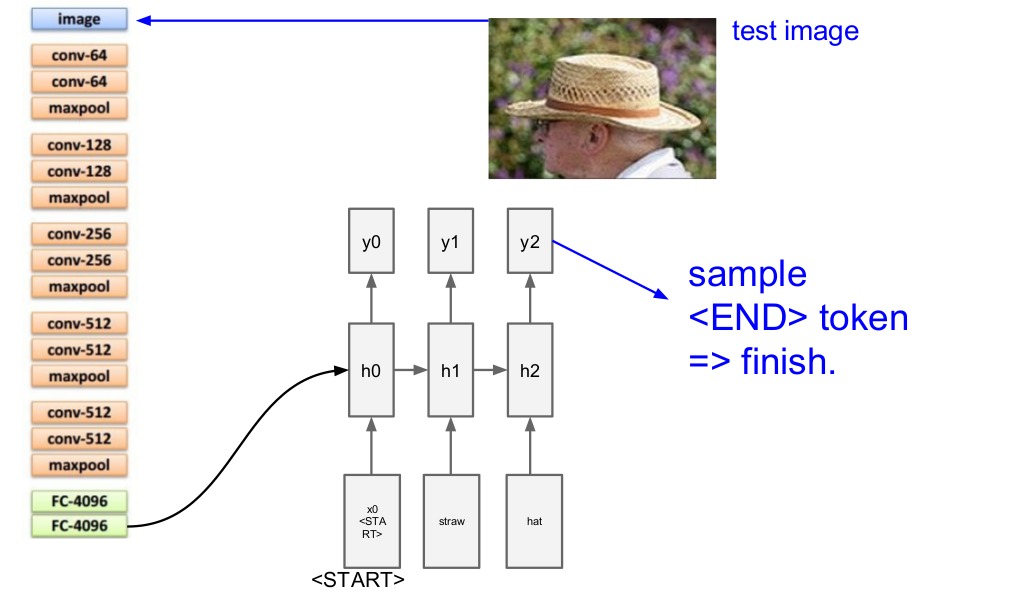
$ 将一张图片放入CNN网络中,整个模型由两个模块组成:$ $卷积神经网络负责处理图像,RNN网络负责建立序列模型。$
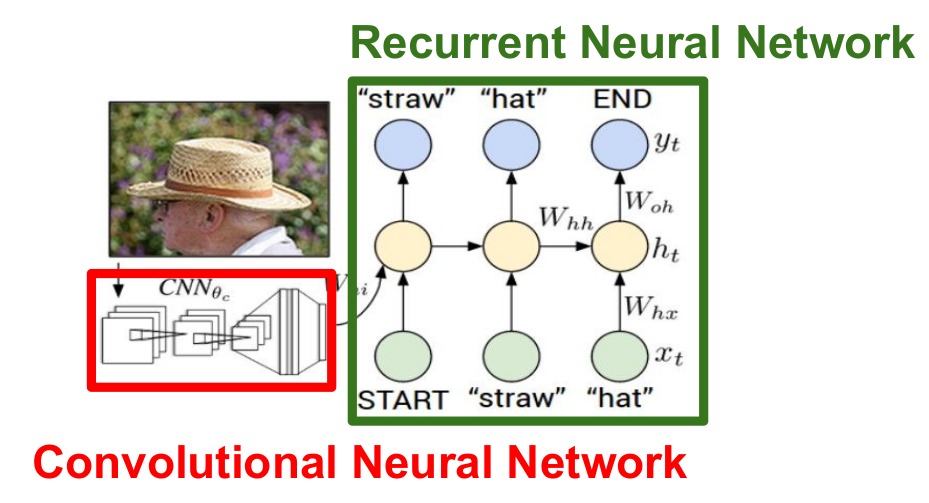
$去掉了卷积神经网络的 FC-1000 和 softmax, 将输出记为V。$ $y向量中的维数等于你的单词表中的单词数+1,+1指的是特别的结束标志。$
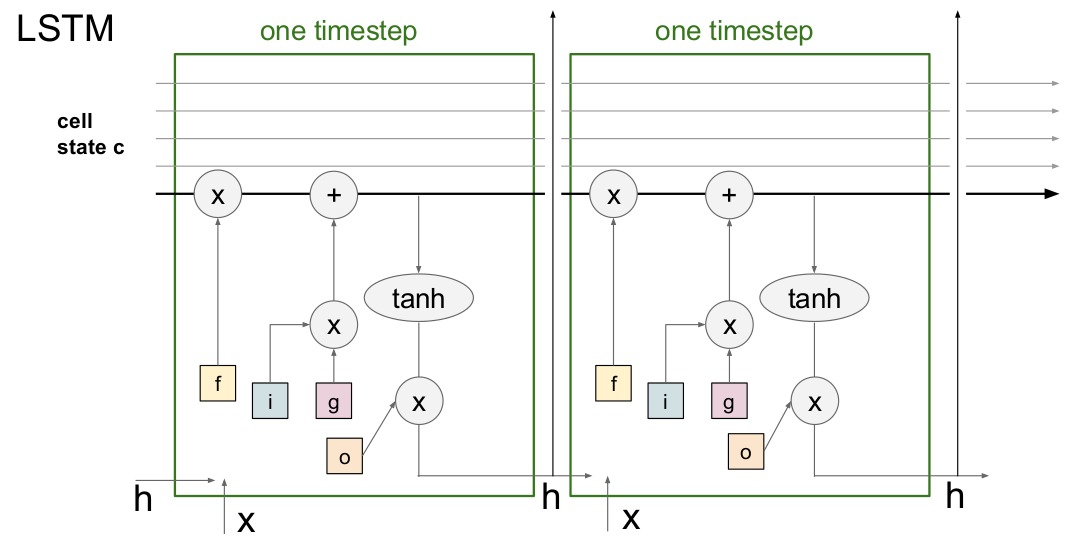
LSTM
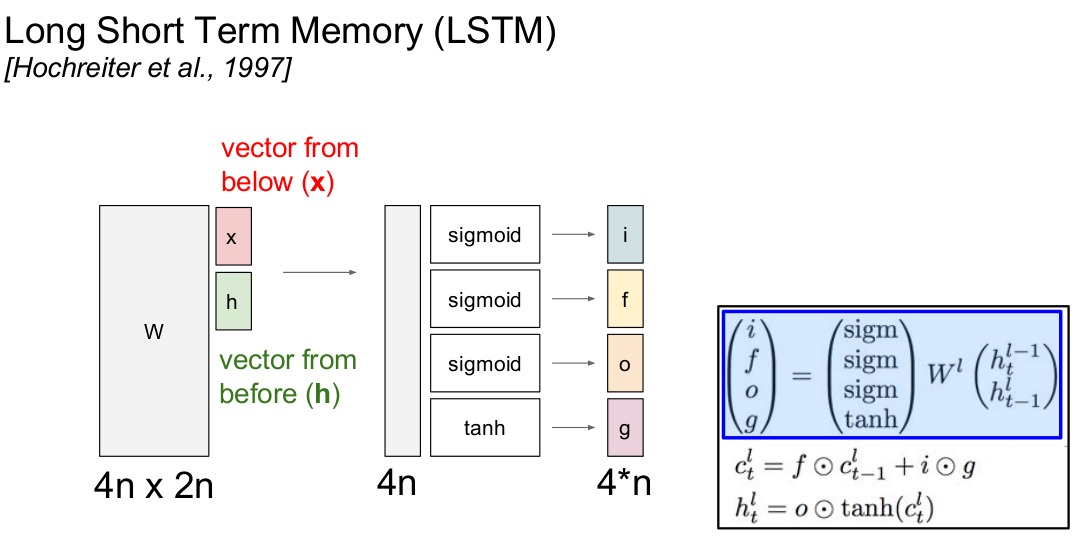
$Long Short Term 网络,一般就叫做 LSTM ,是一种 RNN 特殊的类型,可以学习长期依赖信息$
$所有RNN都具有一种重复神经网络模块的链式的形式。在标准的RNN中,$ $这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。$

$ LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。$ $不同于单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。$





$ i,f,o想象成二进制,不是0,就是1。 $ $ f被称为忘记门,通常把一些细胞状态置0。 $ $ i在0-1之间,g在-1到1之间,给C_{t}加上一个-1到1之间的值,乘以i是为了使函数更加复杂 $ $ 隐藏层参数h更新是以挤压细胞(C_{t})的形式进行,经过o参数调整只有一部分细胞进入隐含状态 $
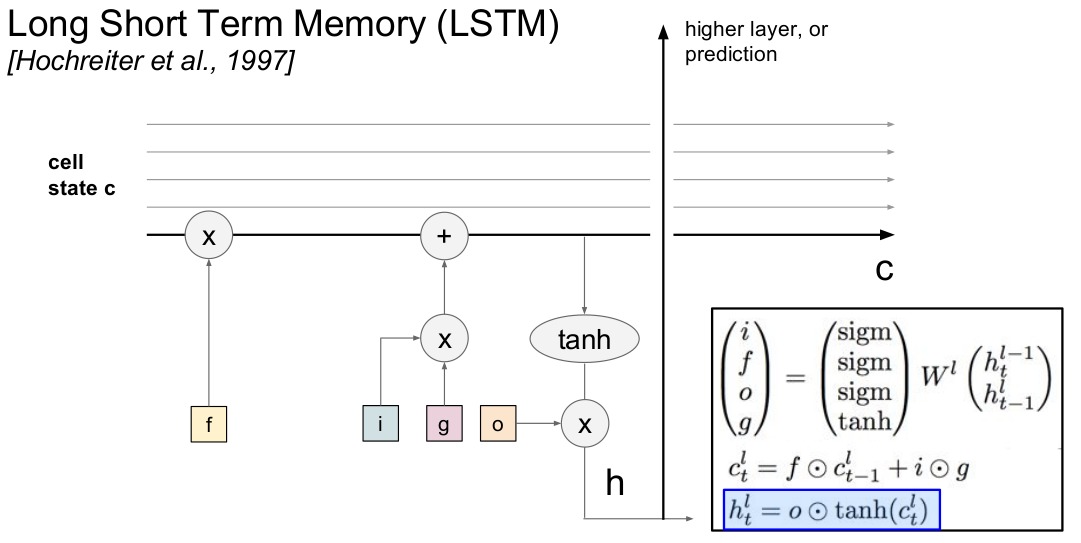
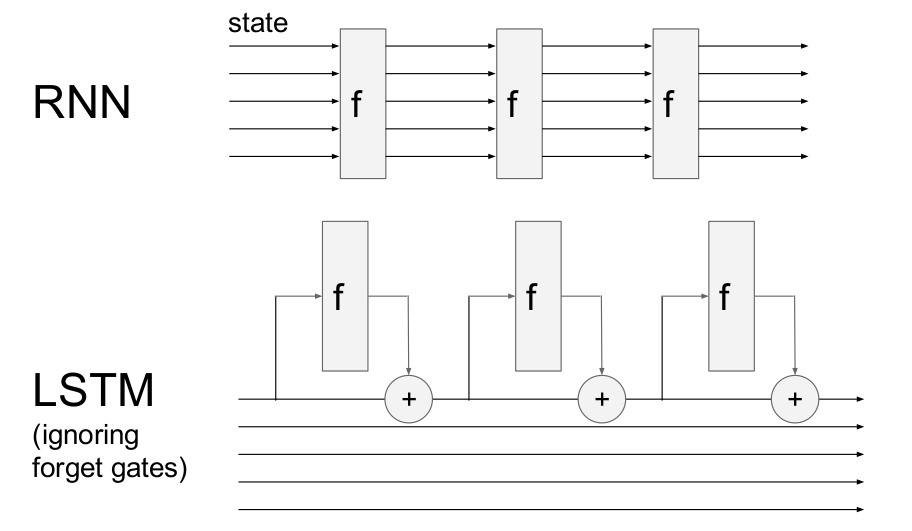
rnn 梯度消失
