#
物体定位与检测
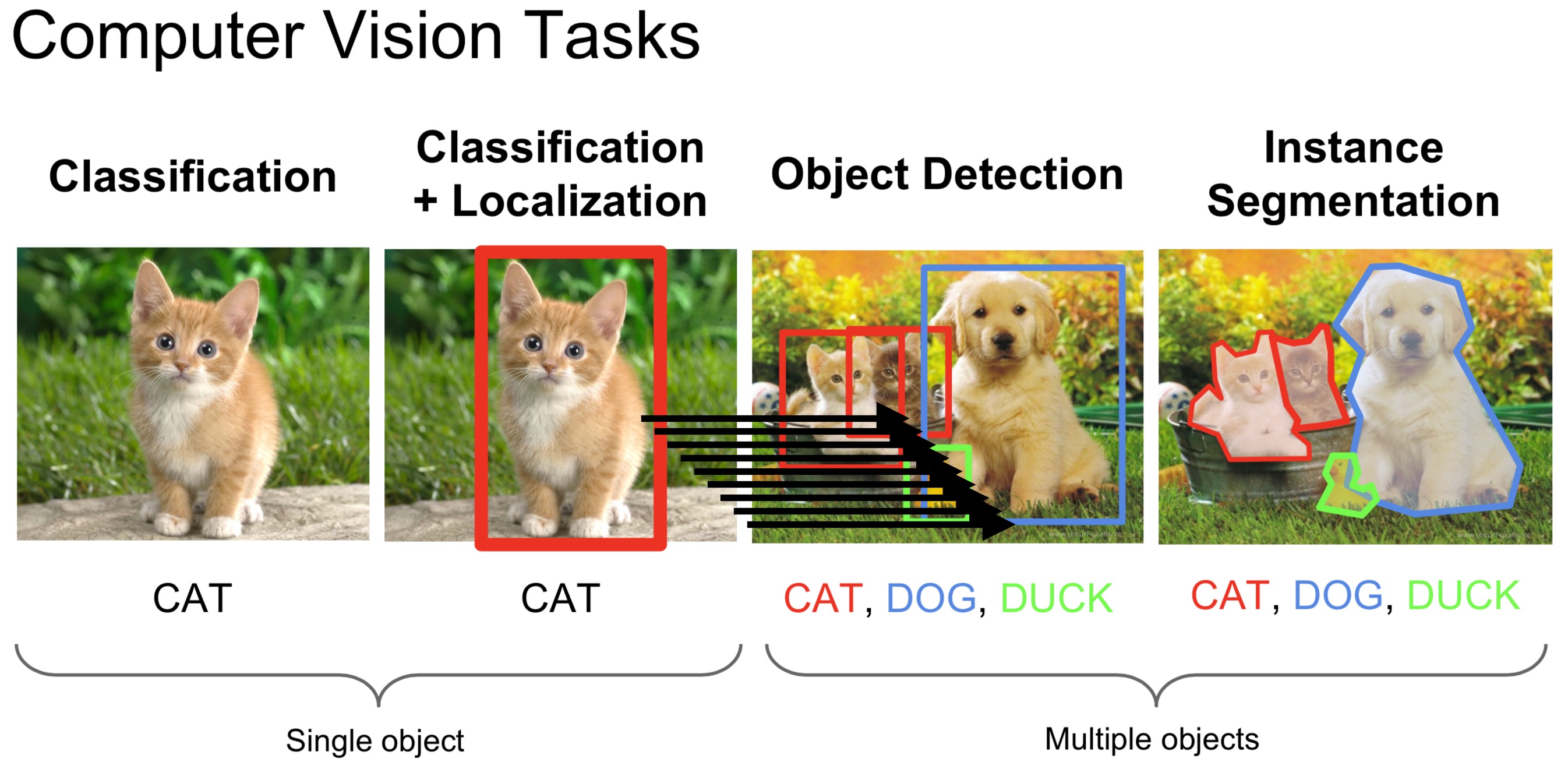
定位:
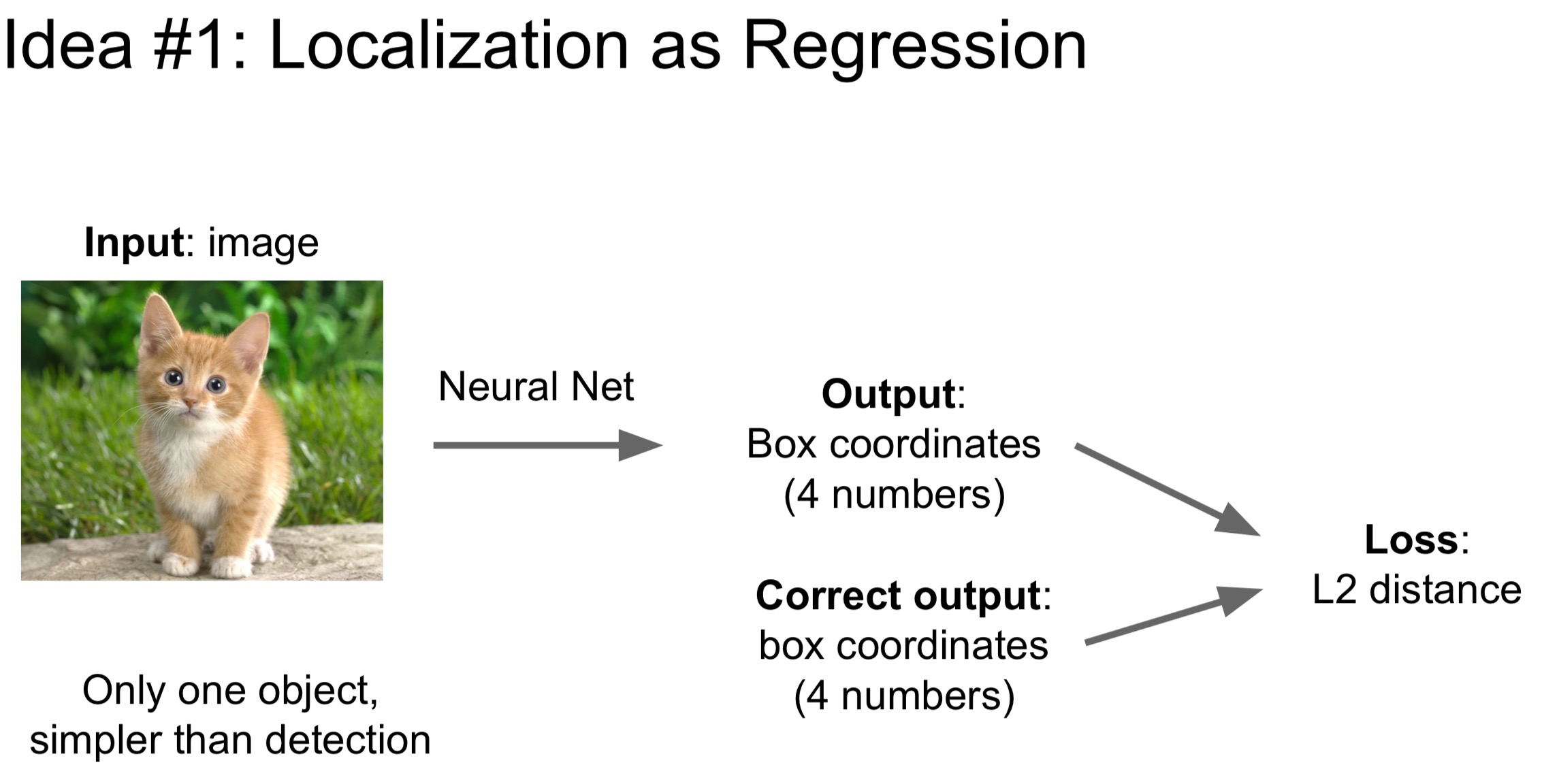
- 回归定位:
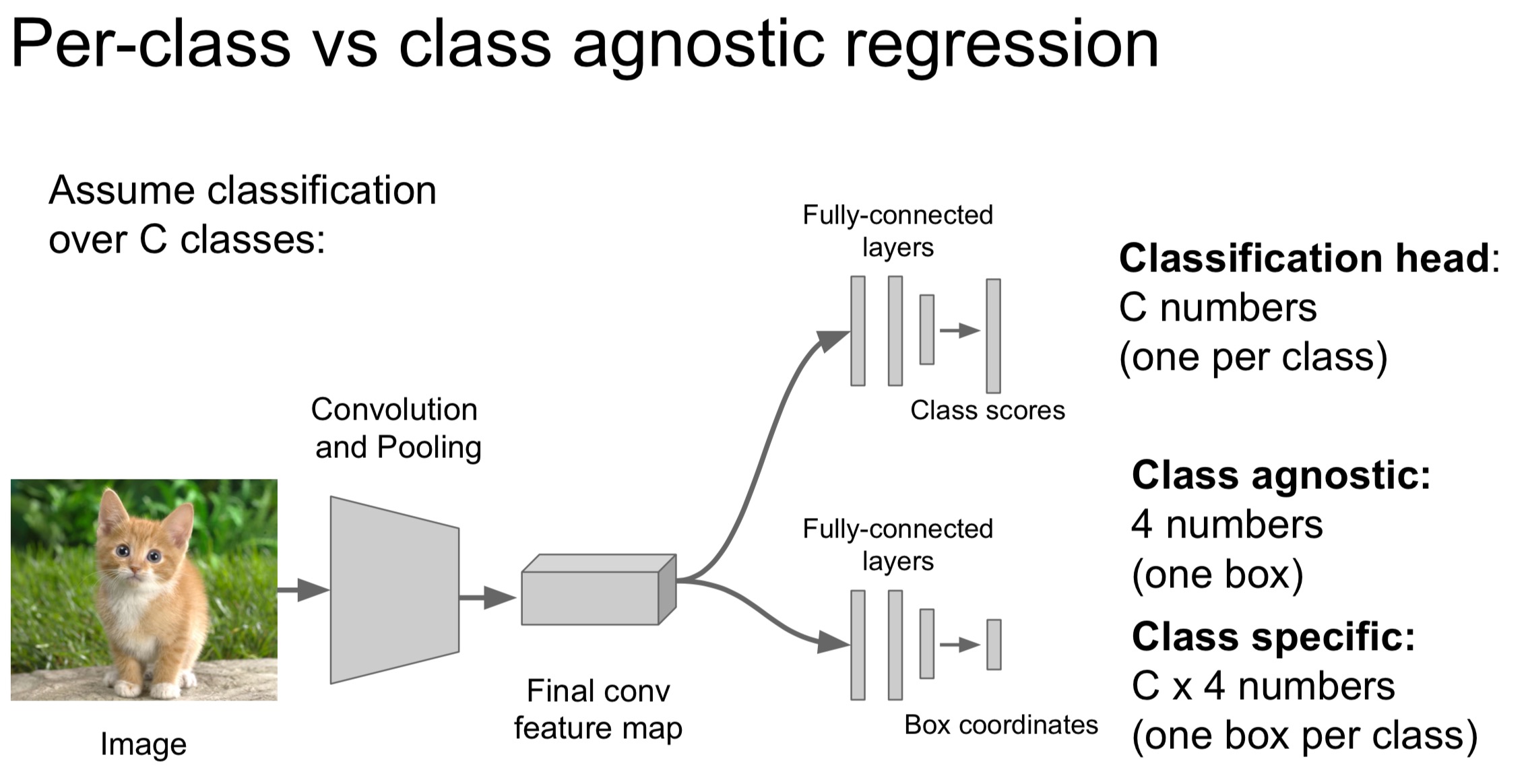
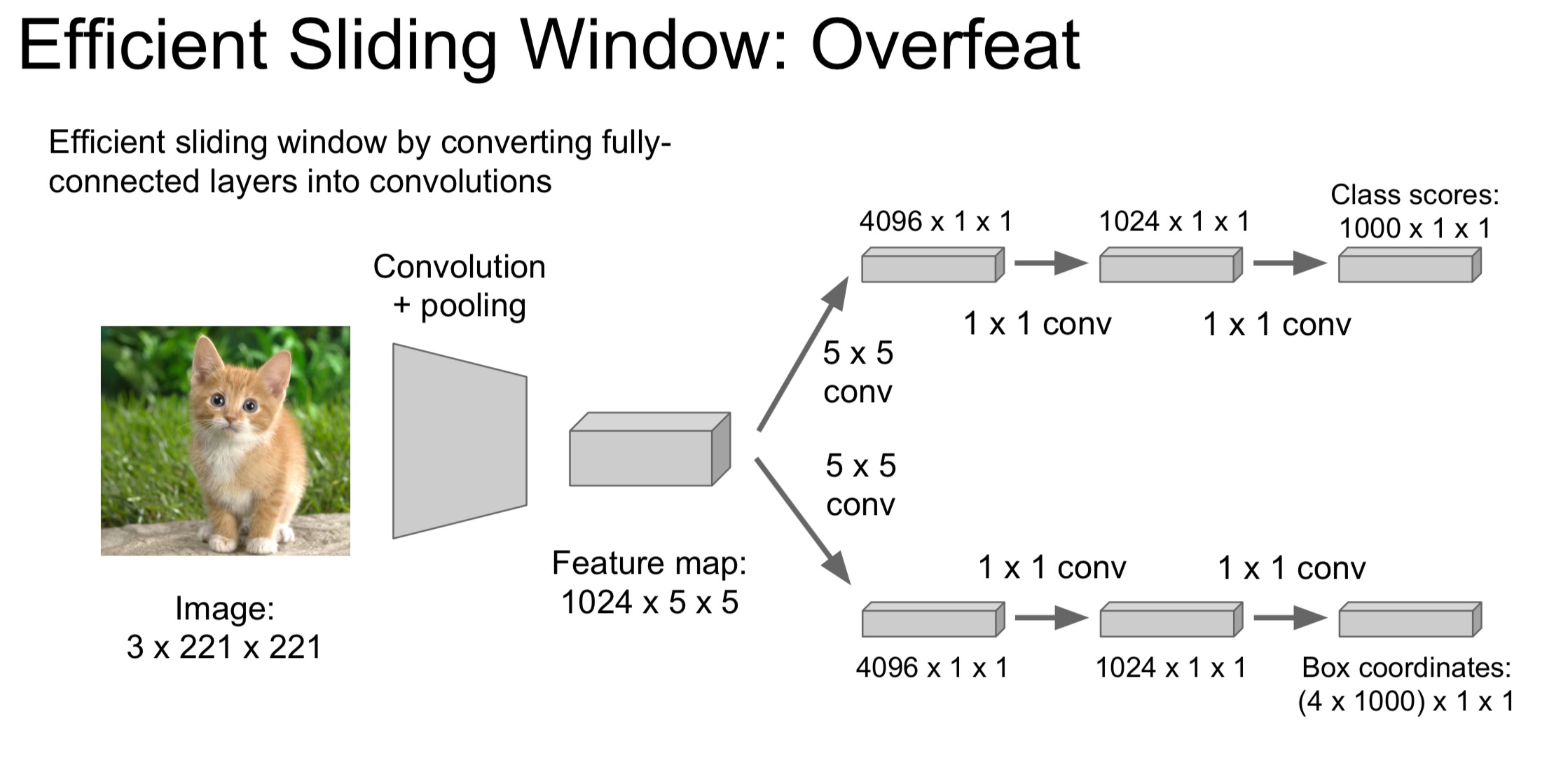
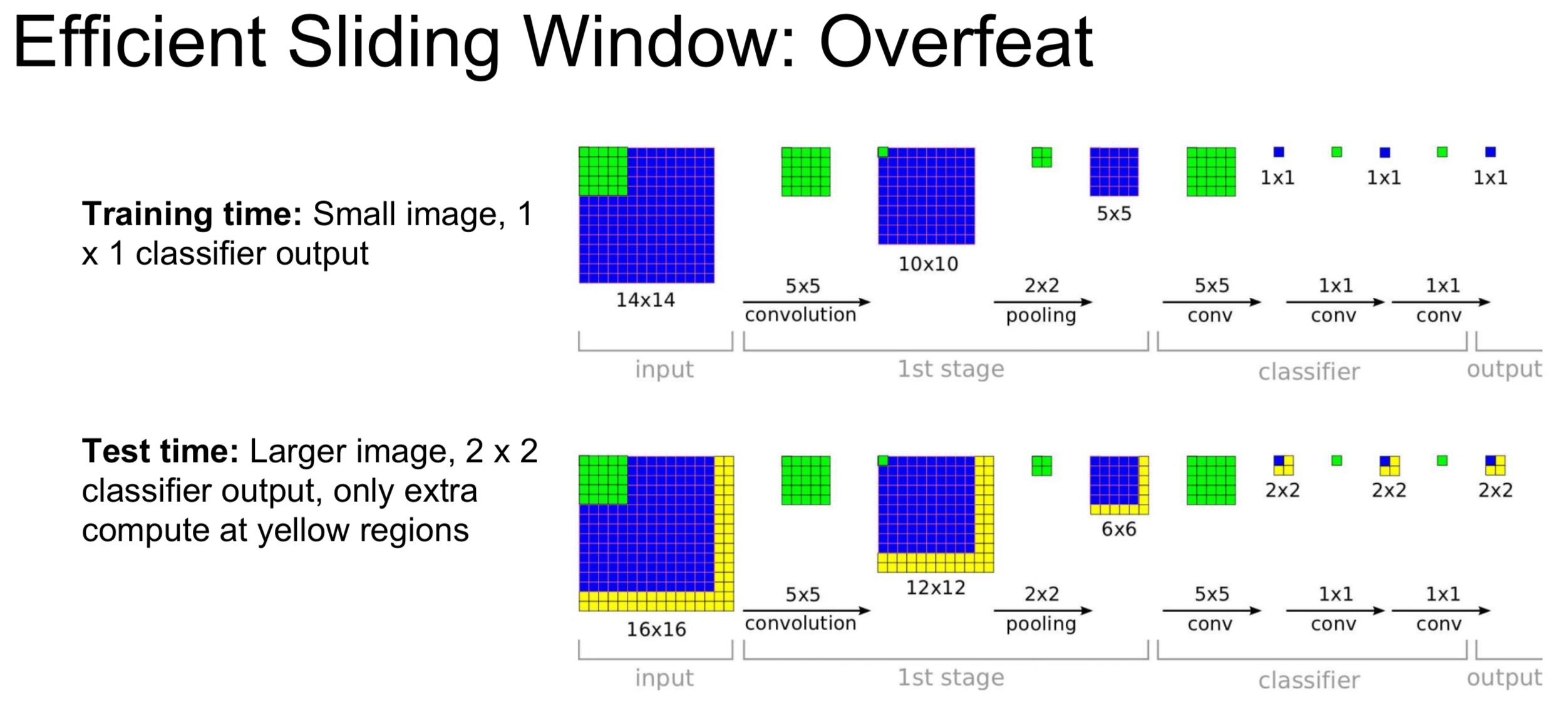
- Sliding Window:将最后的几层FC转化为Conv,适用于不同尺寸的图片。每个滑动窗口作为CNN的输入,会预测一个选框,并给予一个评分,最后结合评分然后把几个选框进行融合。

检测:
Region Proposals: 输入一张图片,输出所有可能存在目标对象的区域。
Selective Search: 从像素出发,把具有相似颜色和纹理的相邻像素进行合并。
RCNN
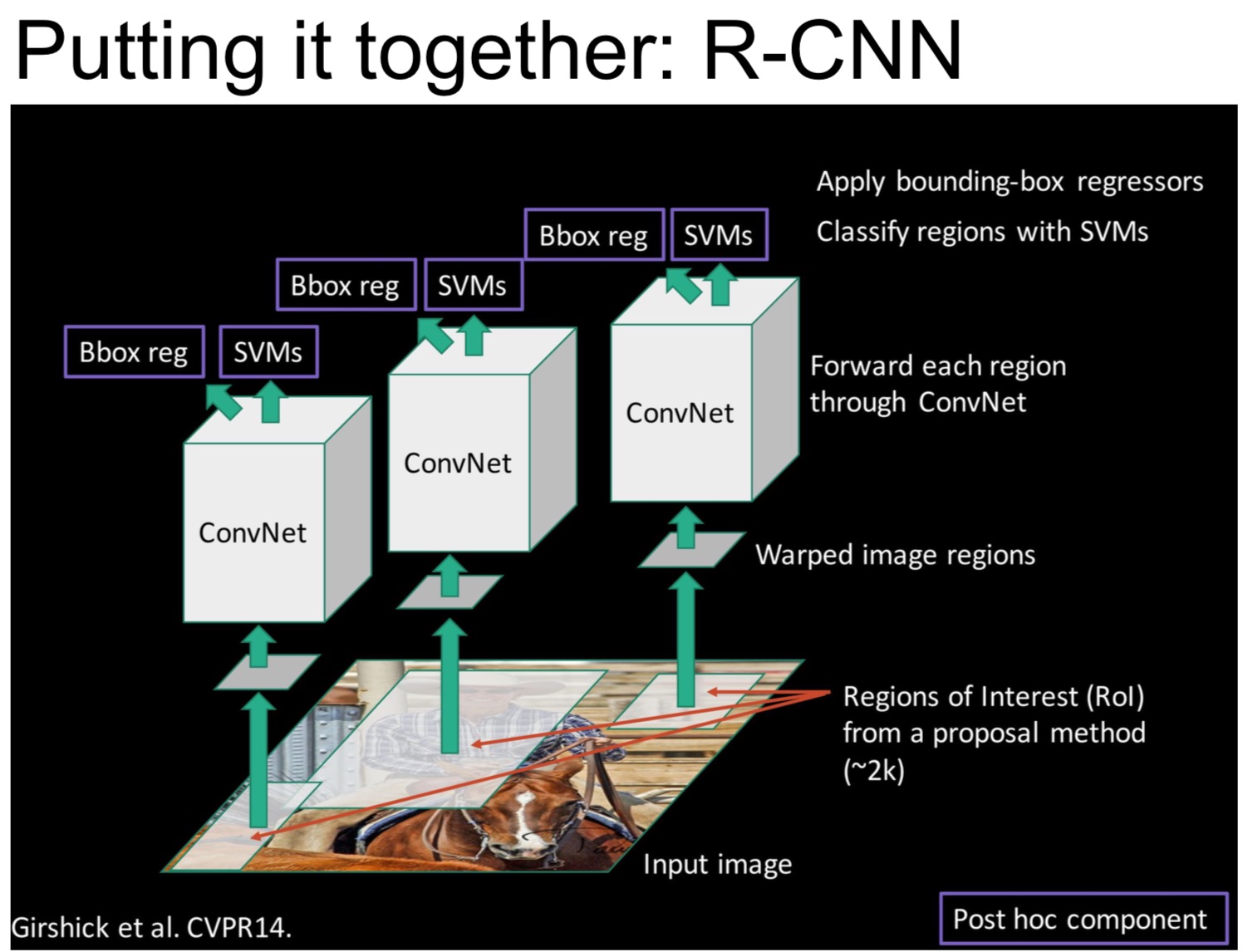
R-CNN Training:
- Step 1: Train (or download) a classification model for ImageNet (AlexNet)
- Step 2: Fine-tune model for detection
- Instead of 1000 ImageNet classes, want 20 object classes + background
- Throw away final fully-connected layer, reinitialize from scratch
- Keep training model using positive / negative regions from detection images
- Step 3: Extract features
- Extract region proposals for all images
- For each region: warp to CNN input size, run forward through CNN, save pool5 features to disk
- Have a big hard drive: features are ~200GB for PASCAL dataset!
- Step 4: Train one binary SVM per class to classify region features
- Step 5 (bbox regression): For each class, train a linear regression model to map from cached features to offsets to GT boxes to make up for “slightly wrong” proposals

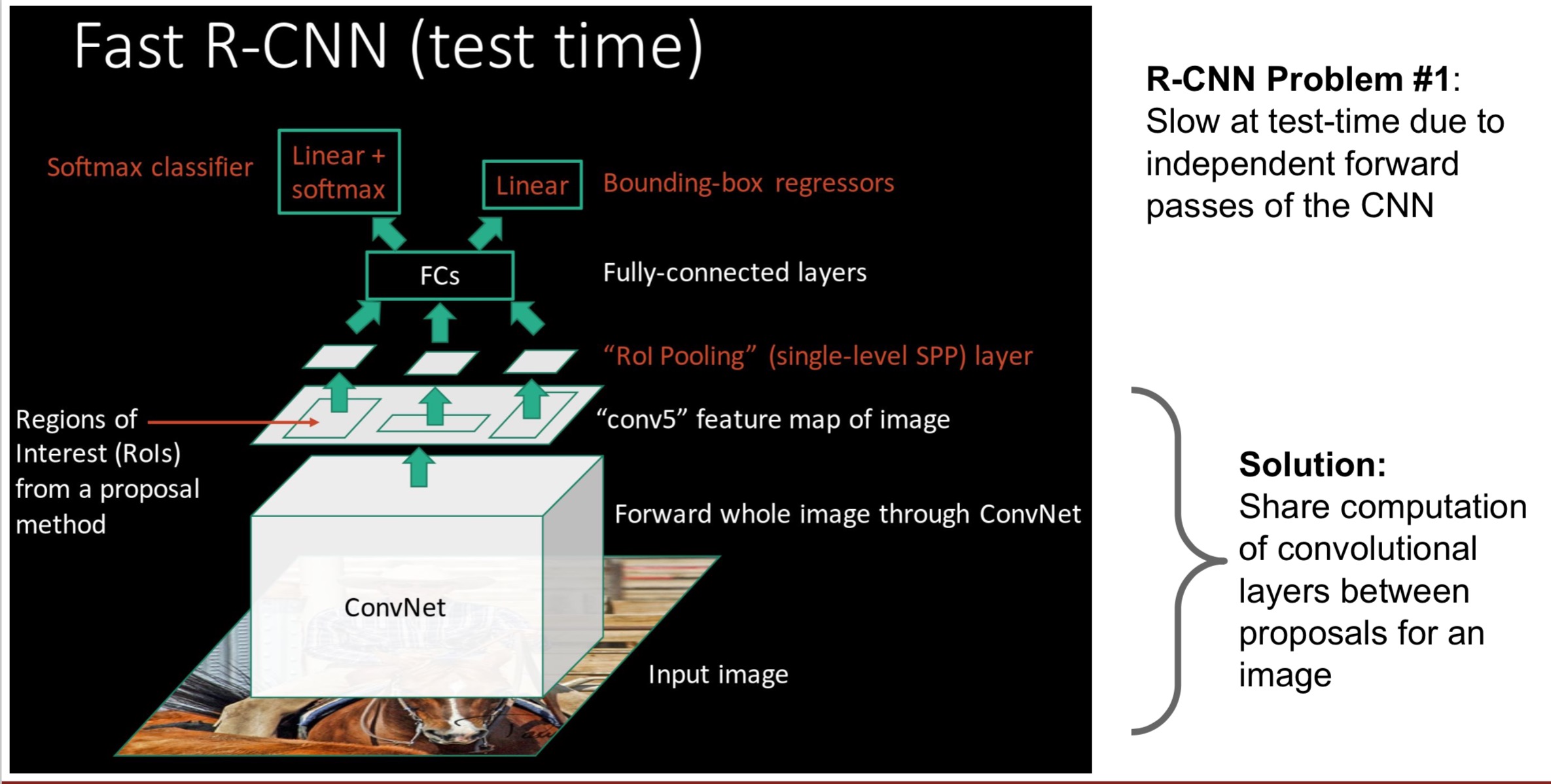
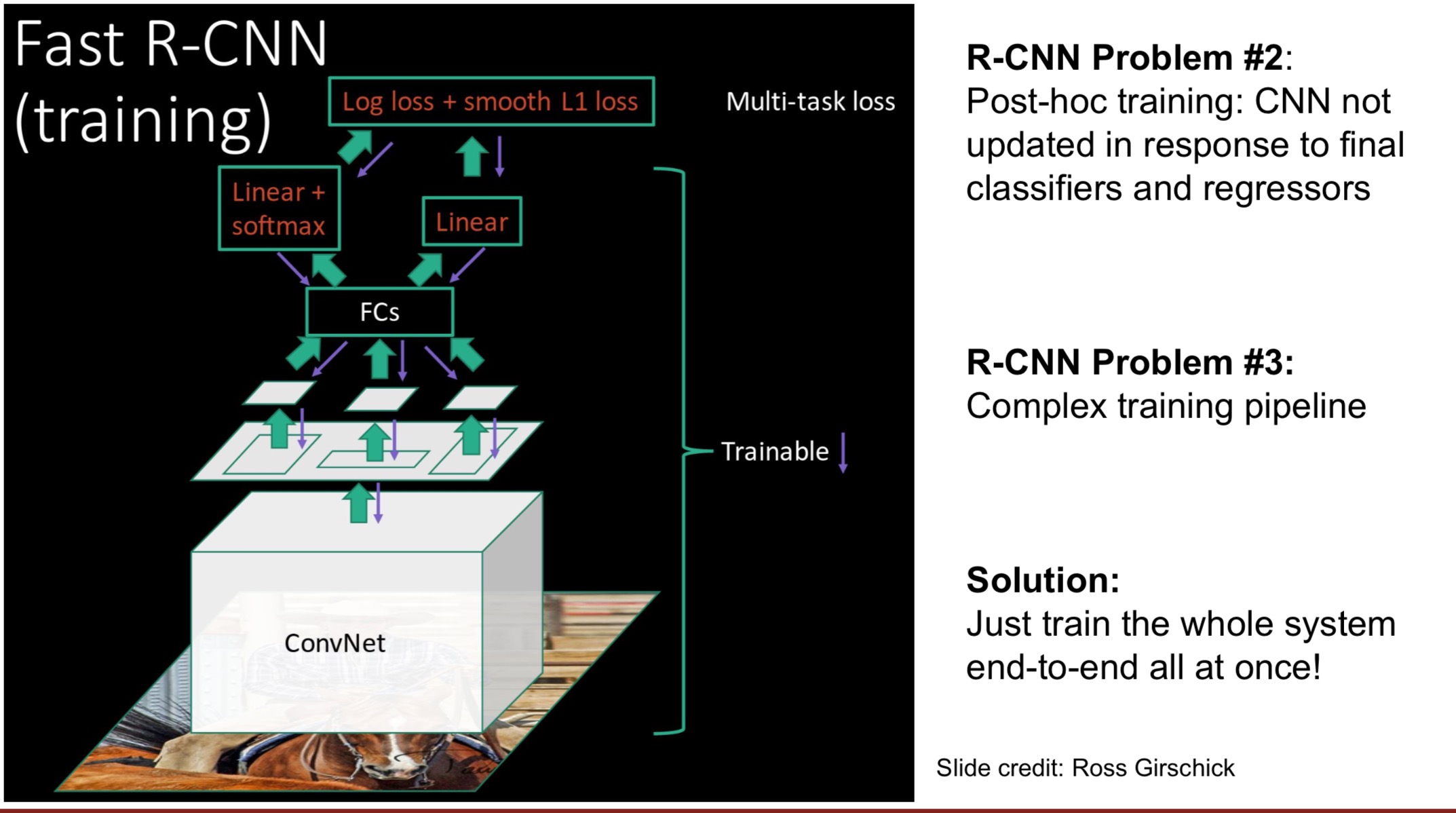
Fast RCNN
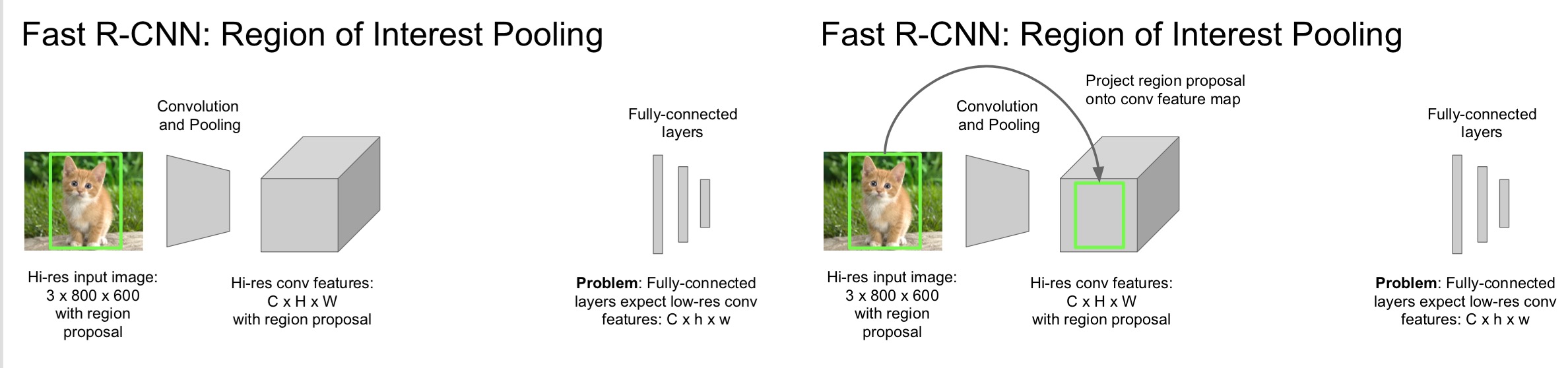
还是在原来的图片上进行区域选取(区域选取太慢了),只能选取到的图片可以直接对应到feature map

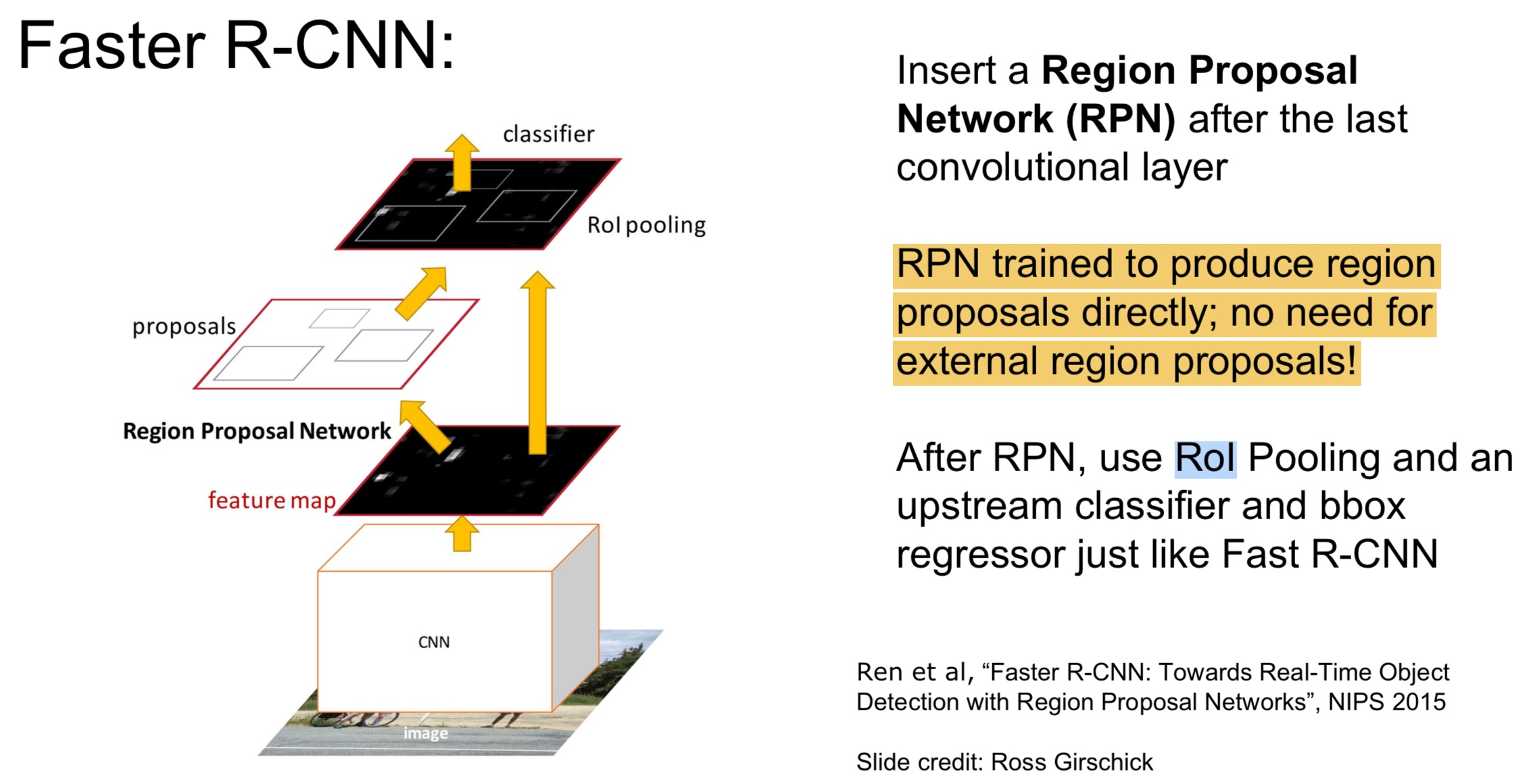
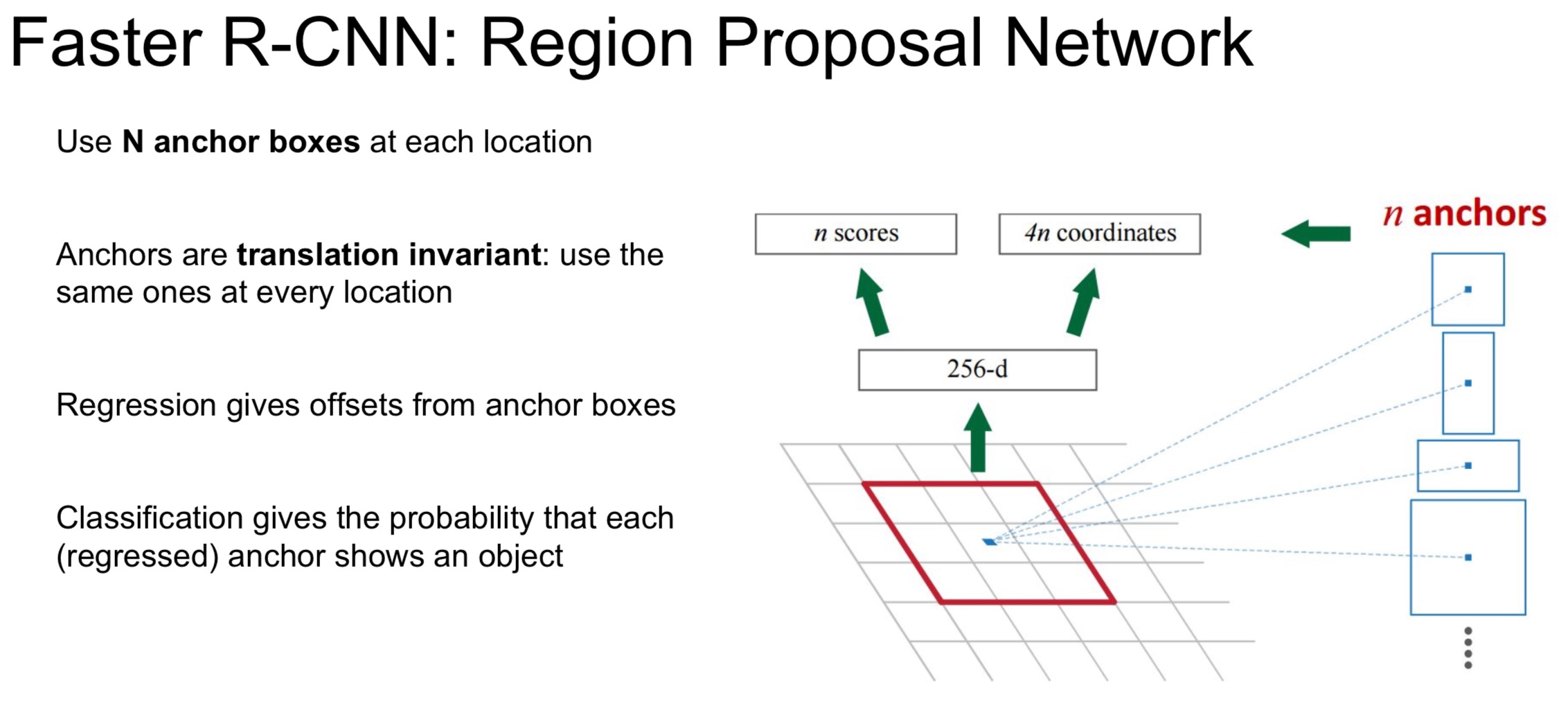
Faster RCNN
在feature map上每个点对应原图,找到原图中对应的区域,进行区域选取